Every Second Counts
If you’ve ever wondered how milliseconds could be used to expose secrets, this one is for you.
In this article, I dive into how timing based side-channel attacks can be leveraged in application security. I’ll show you how tiny delays in system responses can leak valuable information, like open ports and database records. Let’s walk through some theory, and real world examples on actual applications.
Why I find this subject exciting
Hackers love to find & exploit unconventional ways of using technology. The following stuff is no different.
When finding exploits, be it a computer system, a videogame, or a tabletop game, you must always consider what you have at hand. What resources, what tools, what information can we leverage? What data can we give, and what data can we get? What can we do with both?
In games of incomplete information (poker, counter-strike, cybersecurity) it’s your task as a player to not only keep your information exposure to a minimum, but to try and gain information where possible.
Playing these games is exciting. What simple things can we use to gain knowledge, and how could we leverage that? When it comes to hacking, we always think about new clever ways to exploit systems. Do we leverage every piece of information we have to the fullest? For example, how long things take?
What are time-based sidechannel attacks?
To understand what time-based sidechannel attacks are, first we must understand what sidechannel attacks are.
".. a side-channel attack is any attack based on extra information that can be gathered because of the fundamental way a computer protocol or algorithm is implemented, rather than flaws in the design of the protocol or algorithm itself."
Timing based sidechannel is a version of this, where we measure the amount it takes to do a certain computation. When programming, each line of code is translated into instructions for the CPU, when the code is ran. Some more directly than others, but it all comes down to calculations on the CPU. Some of these calculations take longer time than others, for example comparing two strings to each other is much faster than checking if a string appears as a subset of another.
But string comparisons in the end are quite fast. There is an excellent video All in the timing: How side channel attacks work explaining the basics, where it’s mentioned that these calculations take several hundred nanoseconds. Unless you’re in a very specific environment, measuring everything with the margin several hundred nanoseconds simply isn’t possible.
When you start to introduce connections, reading, writing & more data you can get up to milliseconds of time taken on different computations & connections. These are things we can measure and leverage.
Previous work (kiosk.vsim.xyz)
For my kiosk.vsim.xyz tooling, I tried to find a good way to determine if ports are open on devices just using JavaScript. If you want to read more into it, you can read the blogpost here: blog.vsim.xyz
Turns out, you can use http requests to determine if an port is open or not. Looking at the time it takes for the request to resolve implies if the port is open or not. How? If the port is open, and a service behind it responds or cuts the connection due to protocol mismatch, the time to resolve the request is relatively fast. If there is no service responding, the request takes a lot longer to resolve. If the time to resolve is really slow, we can deduct that the host is unreachable from the device you’re running the scan on.
With just a simple measurement of how long a HTTP request takes we can determine if a host exists in a network, and what ports on it are open. To me, this is extremely cool.
Ever since creating that tool, I have been really curious about using time-based tricks to mine information out of systems. The following article comes from the effects of this “nerd-snipe” where I have been unable to let go of the concept.
Mining data with latencies, in theory
I have prepared a database with mock data into it. We can execute a query to find a certain email from the database, mimicking an application looking for an user, for example. The search itself will take time, because the rows are not indexed. But the returning of the results is what is the most interesting here. In theory, if a query is empty, it resolves quicker than if the query returns data in it.
We can suspect that the time it takes for a query to resolve is different if a certain data exists. Using this mechanic, even if we’re not explicitly told the result of a query, we can still determine that something exists in the database if the query runs between the backend receiving the request and responding to it. Let’s create a mockup function to show this behaviour:
from flask import Flask, request
@app.route("/search", methods=[ "GET" ])
def get_user():
# search?email=
email = request.args.get("email")
# If email is given, search the DB for it
if email:
# Note that even if we're not authenticated, the query is being ran
result = query_database(email)
# Result given to authenticated user
if is_authenticated():
return result, 200
# We're not authenticated, so we don't see the result
return "Unauthorized", 401
We’re not authenticated, so on the surface it would seem that there is no way to check if the email we’re looking for exists in the database. However, no matter what our authentication status is, the query is being ran. Because everything else in the function takes roughly the same time each run, the only variance to the time it takes to run the function comes from the database query. This means, that we can measure the time it takes to run the query, by measuring the time it takes from our request to the response coming from the backend.
“Ok, coolbeans, does it work though?” Yeah, we can demo this by creating a small application that works as described. If we now use the mock database created, and hook it to this API, we can see that emails that exist in the database give us different times to resolve than emails that do not exist in the database.
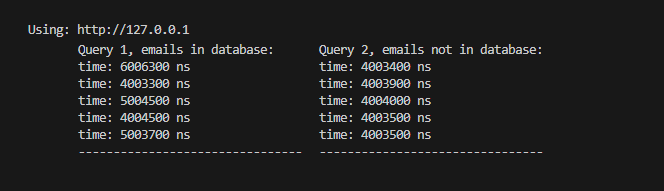
And it seems to work! We can roughly see, which emails are registered and which are not. The latencies vary a lot in relation to each other, however. I suspect that it’s not only because of normal variance in the system, but has to do somewhat also with the lengths of the emails. We can better determine if an email is used by modifying it slightly to one that’s highly unlikely to exist, but not too dissimiliar from the original, and measure their latencies against each other. We will look into this later on this article.
Now that we have an understanding of how to peek under the surface, let’s see if we can find a real application to test this with.
Revealing secrets from beneath the surface, in practice
Because of this new-found fascination in timing stuff, I happened to unlock a new neural link in my head and find the following example.
To understand the context, unless you’re Finnish, I am going to have to explain what this site is. It’s called irc-galleria, and it lives in irc-galleria.net. IRC-Galleria is a Finnish social media-like site that was originally created for users of IRC-chats to share photos and interact with each other. It used to be really popular in the early 2000s, offering features like user profiles, photo albums, comments, and forums. Over time though, its popularity declined due to the rise of global social media platforms that we all know like Facebook and Instagram.
It still exists today, but is mostly used by bots & millenials. I was visiting it for nostalgia purposes, when I noticed something very interesting. You can browse the pictures posted to the site as a catalogue of twenty by visiting: https://irc-galleria.net/pictures/new?page=1
Each page can be visited by adjusting the ?page URL parameter. But as you visit some of the later pages, like page=1337 or even page=133337, you’ll notice that the website loads very, very slow. What’s going on?
As we’re dealing with a black-box, and can’t pop the hood open and take a look at it ourselves, we’re gonna have to hypothize. A sane way to do this cataloguing would be to take the photos that are in range n..n+20, where n is the page number. It could look something like this:
SELECT *
FROM images
WHERE image_id >= (
SELECT image_id
FROM images
ORDER BY image_id
LIMIT 1 OFFSET ?
)
ORDER BY image_id
LIMIT 20;
Where offset can be set to something like (n*20) - 1. For page 4, this would mean offset of 79. But if we look at the time it takes to resolve these requests, we can kinda guess something is off here.
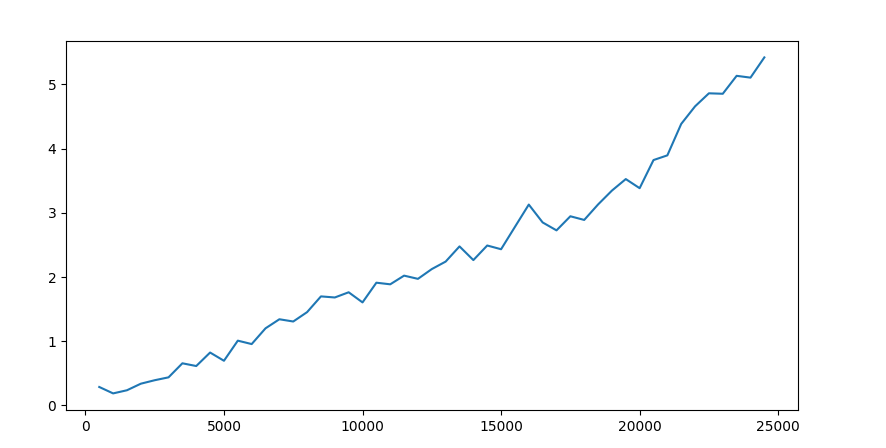
We can see that the resolve time of the request rises in accordance to the page number, which would implicate that the images are first all loaded into the memory, and then programmatically pruned to get the last 20. This is slow. It could look something like this:
per_page = 20
offset = (page - 1) * per_page
results = database_results[ :offset + per_page ][ -per_page: ]
While we can’t get an actual look inside the hood, from the way the pages load we can guess-timate how the engine is built. This means we have indirect information exposure, and while it isn’t that useful in this example, we can come up with cases where this kind of information exposure could be potentially “a bad thing”.
NOTE ABOUT THE IRC GALLERY
So while getting the figure above, I went from ID 0 to ID 30,000 and noticed something peculiar. Around the pages where we cross autumn of 2011 with the picture dates, the gradual increase of the time it takes for the page to load jumps up to near 30, and stays almost at that until the end of the pages.
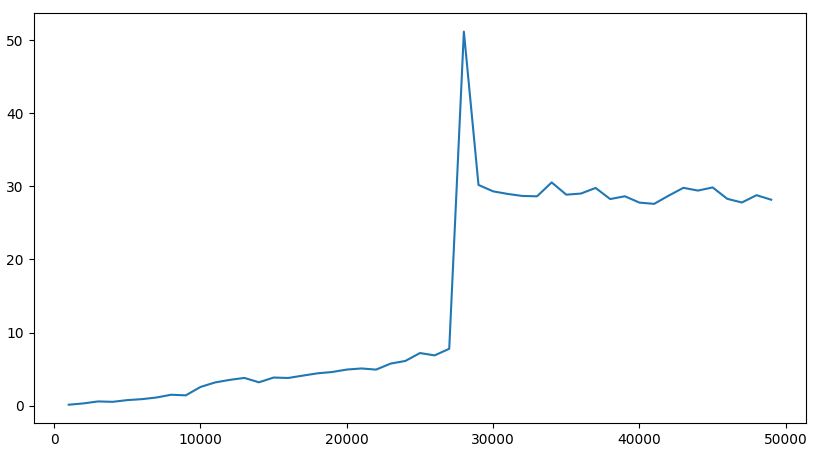
I will be completely transparent with you – I don’t know why this happens. My theory is, that the way the backend or database handles images past a certain point. This could be due to the storage for the images being elsewhere, as I said, I honestly have no idea. Until that point, which is around page 27331, they do grow lineary though, so I do not think this completely invalidates the findings above. When I first came to find this, I only checked the last page & the first page, interpolated and deemed it grew in increments that represented somewhat linear flow. As an apology, have this meme I made when I first found it:
Can we make it a security issue?
[TQN - 13/12/2024, 17:15]
what i mean is that real world scenarios are
usually too dirty for this kind of approach to work
its like making a semi conductor in a clean room
and then trying to replicate it in my dusty attic
After being kindly convinced that mining user-information & other data out of real world, production applications would be impossible, I wanted to find an application where we could actually leverage this method for real world impact.
I decided to use a bugbounty engagement as the subject for this research. Unfortunately, even though the following example was “accepted” as a P5/Informational without the aim to fix it, public disclosure wasn’t accepted. I will be referring to the vendor as [REDACTED].
I had previously reported to [REDACTED] an email-enumeration from their forgot your password? functionality. Their API would produce an error on the site if the email was not in use, and display the correct "We've sent you an email to reset the password, if this email has been registered to an account" if an email was in use. Late 2024 [REDACTED] decided to build a new login system, and as such, this bug has been fixed.
After testing the new site for a bit, I noticed, that [REDACTED] sends out an email every time you request a password reset. We can create a pseudo-code of the mechanism in the backend:
...
user_email = request.data["email"] # Parse JSON from HTTP Request
if email_registered( user_email ) # Check the DB for the email
send_password_reset_link( user_email ) # Send out the link!
return
else:
# Email not registered -- do nothing
return
...
In both cases, the API response is the same, but an additional computational cost is added if the email is registered. The database query, admittedly, can be a bit too fast to notice a difference of with the added variance in latency that comes from multiple hops. But sending out an email? Slow!
Slow enough to reveal secrets? yeah! We can see, that there’s a clear difference between requests:

We can see that with manual testing that the email that has been registered resolves in the API ~200ms slower than the email that has not been registered on the site. We don’t even have to look at the response – as long as it’s 200 & accepted, we know they sent out an email if the address is valid. We can, through the time it takes to resolve the request, enumerate which emails are already registered on the site.
Dusty attic gains 1 point. Score is now one to nil.
Let’s script this to prove we can use this to enumerate emails programmatically. First we need to create the reset request to the backend:
import requests
#
# Reset password
#
def send_reset_password( email ):
url = [REDACTED]"/v1/api/reset-password"
_json = { "email" : email } # target email
_headers = { ... }
response = requests.put(
url = url,
headers = _headers,
json = _json
)
return response
After which we can measure the time it takes for the HTTP request to resolve. We can call the function and take a time before the call and after the call.
import time
# Get Latency of the request, in milliseconds.
start = time.time() * 1_000
response = send_reset_password( email ).text # Reset-request function
stop = time.time() * 1_000
These latencies & timings are of no use, if they’re not stored. Let’s handle that too:
TIMINGS : dict = {}
...
global TIMINGS
# Store results per target tested
if email not in TIMINGS:
TIMINGS[ email ] : list = []
TIMINGS[ email ].append( stop - start )
As I mentioned before, different length of strings take different times to handle in the backend. To ensure the different lengths of the emails don’t interfere with the measurements, we must test an email against a baseline. We can create the baseline by changing a few characters in the email, still keeping it generally in tact, but trying to change it into a format that wouldn’t appear organically. We can do this by for example changing 1 letter in the domain of the email. [email protected] would then become [email protected]. Of course someone could register the domain, and create a list of emails, and then register to [REDACTED]’s site with them, which would interfere with the testing.. but we can.. generally assume this hasn’t happened.
def leetify( email ):
#
# Change Email address into a one that's most likely non-existing.
#
deconstructed = email.split( "@" )
# Email should be as long as the one we're testing.
# Longer emails take longer in the query from the DB.
reconstructed = deconstructed[ 0 ] + "@"
reconstructed += "1" + deconstructed[1][1::].replace("a", "4")
return reconstructed
With already these functionalities it’s possible to start looking at the differences between different emails. See this code for further implementation:
https://github.com/Vsimpro/esc-labs/blob/main/scripts/enumeration.py
We can then run the script against this live system, and see how accurate we can get. For the screenshot below I modified the script to check if the email is registered by making a separate list to compare to. It’s indicated by the second column, stating True for registered and False for unregistered.
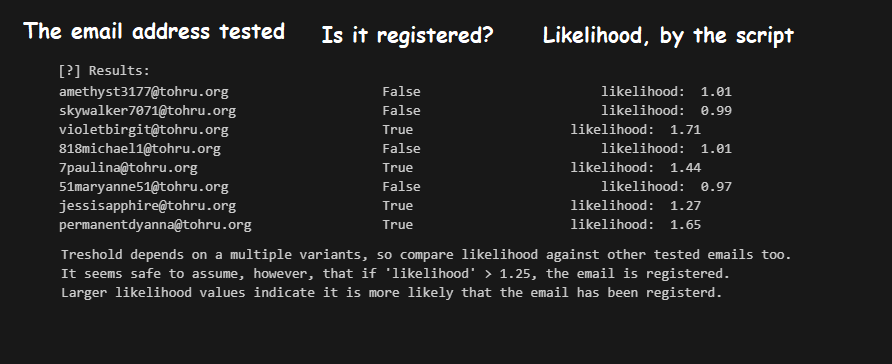
Looking at the results it gives, it’s clear there’s a way to differentiate between email addresses that are registered, and the ones that are not. The emails that are not registered either fall shy of 1.0, or are just barely on it. The emails that are registered produce values well over 1.25. Email enumeration achieved!
Why is email enumeration an issue?
Email enumeration is a type of attack, in which it’s possible for an malicious actor to enumerate a list of emails used for accounts in a system. Why does it matter?
- Users of a system will be vulnerable to spearphishing Because it’s possible to get a list of emails that are registered to a service, it’s possible to launch a targeted phishing campaign.
- Users of a system can be now more vulnerable to account takeover attempts With the list of emails it’s possible to do more targeted attempts of account takeover on services.
- Chaining a vulnerability in which an accounts email is needed There could be an IDOR in which you can view other accounts data with a valid email address. For this, you’d need a valid set of emails, which could be possible to get through email enumeration attacks.
Valid lists of emails are worth money to criminals. In 2023, hackers were able to scrape emails of 400 million Twitter users. Lists like these, where a site has been scraped for emails go for sale on sites like BreachForums constantly.
To ensure your security posture doesn’t appear weak, the possibility for email enumeration is something you should consider mitigating. Let’s take a look at how this could be achieved.
Possible mitigation?
Let’s take another look at what we can hypothize happening in the backend. Let’s look at it in the context of a flask webserver function.
@app.route("/register/", methods=[ "GET" ])
...
user_email = request.data["email"] # Parse JSON from HTTP Request
if email_registered( user_email ) # Check the DB for the email
send_password_reset_link( user_email ) # Send out the link!
# Return
return "Password reset sent if email has a registered user", 200
...
We can see that the part which is causing the measurable delay is the checking & sending of the email. In theory, we could offload this in somewhat~ consistent time, for example pushing it to RabbitMQ or another job queue.
# File: app.py
#
# Take in the Email
#
@app.route("/register/", methods=[ "GET" ])
...
user_email = request.data["email"] # Parse JSON from HTTP Request
# Send email to be checked & possibly send out the reset link
message = json.dumps({ "email": user_email })
channel.basic_publish(
...
body = message,
routing_key = "email_queue",
...
)
# Return
return "Password reset sent if email has a registered user", 200
# File: email-check.py
#
# Elsewhere, check if the email is registered and send out
#
channel.queue_declare(queue="email_queue", durable=True)
# Function to process the message
def callback(ch, method, properties, body):
...
email_data = json.loads(body.decode())
if email_registered( user_email ) # Check the DB for the email
send_password_reset_link( user_email ) # Send out the link!
...
We must do the check & sending of the email in a separate runtime, to off load the measurable computing time of these tasks. In an API endpoint, where the response doesn’t change, this is possible. But what if the response changes based upon the parameters? Let’s take a look at an earlier example:
@app.route("/search", methods=[ "GET" ])
def get_user():
# search?email=
email = request.args.get("email")
# If email is given, search the DB for it
if email:
# Note that even if we're not authenticated, the query is being ran
result = query_database(email)
# Result given to authenticated user
if is_authenticated():
return result, 200
# We're not authenticated, so we don't see the result
return "Unauthorized", 401
Fixing this function into a form that doesn’t reveal any information to unauthenticated is relatively easy. If user is not authenticated, do not make the database query. It would look like this:
@app.route("/search", methods=[ "GET" ])
def get_user():
# We're not authenticated, so we don't see the result
if is_authenticated():
return "Unauthorized", 401 # Early return to reduce compute!
# search?email=
email = request.args.get("email")
# If email is given, search the DB for it
if email:
# Note that even if we're not authenticated, the query is being ran
result = query_database(email)
# Result given to authenticated user
return result, 200
We want to return early, to reduce the compute time. This control of flow minimizes the risk for this attack vector.
Conclusions
We can reveal all kinds of things, if we really pay close attention to details!
By measuring the small details, we can infer how a backend processes a request, whether data exists in a database, or even what ports are open. These are “attacks” that do not rely on exploiting the traditional security flaws, but rather can be exploited through understanding the subtle behaviour of a system.
Even in the production environments, where latencies vary and network noise is greatly present, these techniques can still be observed and leveraged. Even in the dusty attics of real-world applications.
We can see that mitigation isn’t impossible, but needs some thought. Trying to strive for code that runs on O(1) time is noble in any case, but can in this case serve the security as well.
Thank you for reading! Hope you learned something!
- Vs1m
Bonus & notes
If you wish, you can try out these attacks yourself. I’ve created some sample code & labs to try these attacks against into this repository: https://github.com/Vsimpro/esc-labs
I hope you have as fun with them as I have!